


Zero downtime deployment
A few weeks ago I was discussing with a colleague about how we could deploy our PHP application, and started to wonder if it’s possible to make our deployments not to cause any downtime? And how?
We quickly jumped to the same negative conclusion, mainly because… database, you know. Sounded obvious to both of us, but maybe this deserves some more thoughts.
Some background
Before going further, let’s describe a typical PHP deployment. Here is what I’ve seen most of the time :
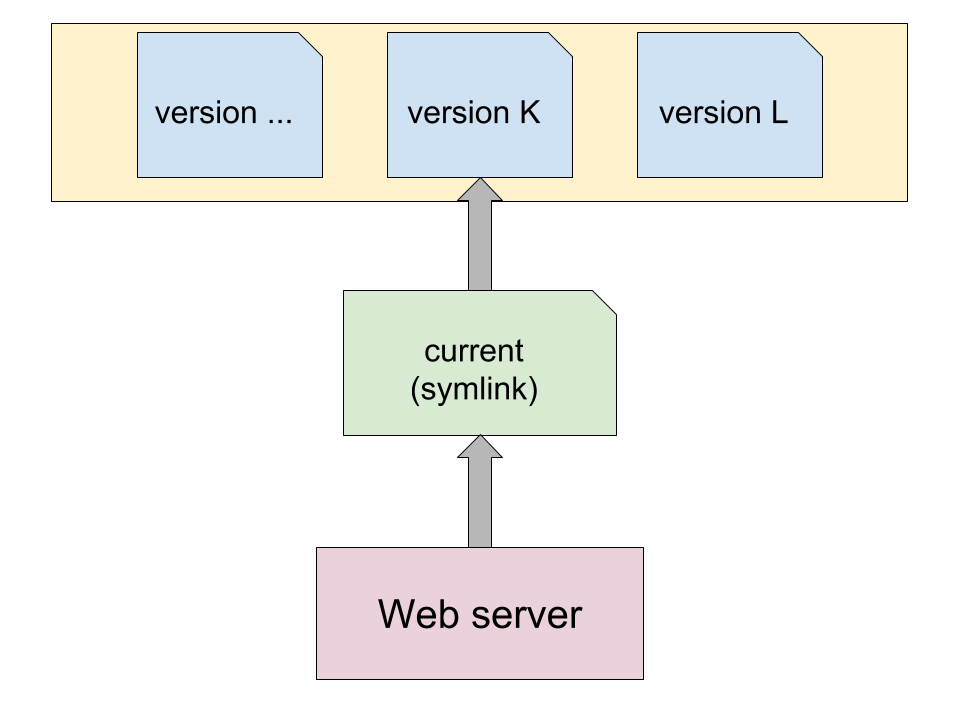
Basically, the web server is configured to use a symlink as document root. That symlink points to the current version of the application (the one which is live, in our case it’s version “K”).
Whenever we want to deploy a new version (here “L”), we have to copy its source code to the releases directory, then change the symlink to point to that new version. When done properly, it’s an atomic operation, which means no downtime occurs.
In real-world applications however, there are some other things that need to be taken care of for the new version to be deployed. They can be splitted in two categories:
- the ones that can be done without compromising the live application (composer install, generation of application filesystem cache / web assets, …)
- the ones that can’t (running database migrations, clearing key-value storages like Memcached, …)
The first category is harmless, it can be done in some sort of build step.
The second one has to be done during a downtime: visitors will see a maintenance page until all operations are finished. All those operations are also transactional, which means they will either all succeed or the deployment will enter into a rollback procedure. The goal of this rollback procedure is to put back the system in a state where it can run version “K” again. If you need to take a deep breath, that’s during this downtime : it’s the most sensible part of your deployment.
Why do we need this downtime?
The main reason for it is to avoid race conditions.
Without it, a visitor might start loading a page of the “K” version while database schema has already been migrated to the one required by “L” version. Another visitor might request a page of the “K” version that’ll populate some shared cache you had just cleared. This can result in nasty bugs and compromise the application even after it has been deployed. That’s why a maintenance page is instead shown during operations from this second category.
Database migrations
Until now the only tool I’ve used for database migrations is Doctrine Migrations, through its Symfony Bundle. In a nutshell, it allows you to create migration classes with an up() and down() methods. Each migration has a unique version number which is persisted in a database table, so that Doctrine can track which ones have already been applied.
Here is what the bundle documentation says:
Of course, the end goal of writing migrations is to be able to use them to reliably update your database structure when you deploy your application.
Concretely, when your code changes affect entities, you can ship a migration class in the same commit. It will then be applied during application deployment.
Back to our deployment, let’s say version “L” contained a database migration. It has just been deployed and a business-critical part of the application is down. This is not a failure due to the database migration, that’s why it didn’t rollback to version “K” during the downtime.
So in the hurry we deploy version “K”, we are prompted with a message:
WARNING! You have 1 previously executed migrations in the database that are not registered migrations.
However the deployment passed through. Good, we think we finally made it but now the entire website is down.
What happened?
The problem here is that version “K” misses a migration class from version “L”, our deployment process couldn’t downgrade database version. It just displayed a warning and continued. Now version “K” is running with a database schema it doesn’t support: the website crashed.
We could have guessed it and come-up with working alternatives :
- enable maintenance mode, cd to version “L”, migrate database schema one level down, deploy “K”
- find the issue, create, release and deploy version “M”, containing a hotfix
- … or create, release and deploy version “M”, with a new migration class that reverts the previous one
This is either hacky or doesn’t sound fast enough though… Our priority is to get the website up and running again, there is no time to investigate or start coding something. Why can’t we just “deploy K”?
Decoupling database migrations
The solution for this resides in better separation of concerns. Let’s try to make database migrations a standalone brick of our infrastructure.
Extracting database migrations
As we just saw, database migrations don’t mix well with application source code. Our database is versioned through a migration_versions table and our application uses something like GIT. An application version is a state, while a database migration expresses a transition (between two states).
The only thing that should be provided by the application is the database version it requires. Assuming you have a Symfony project:
# app/config/parameters.yml
parameters:
# ...
database_version: 20160301101156The number we want to put there is the version of the latest migration class we currently have. Then we can grab the migration folder and extract it to its own repository.
Executing them outside deployments
Now that our database migrations are extracted from our application, we can consider decoupling them from deployments too. Let’s go through practical examples.
Adding a table / column
Doctrine won’t complain if there is a table / column it has no mapping for, so:
- execute your migration
- update your code (make sure to also update the database_version parameter)
- deploy
Removing a table / column
Here it’s the other way around:
- update your code
- deploy
- execute your migration
- update the database_version in your code
As a side note, here I’d suggest to do a soft-deletion. Instead of dropping the table / column, rename it to table_old / column_old. Also, even though the entity mapping is removed, the code doesn’t have to be dropped yet. You can add deprecation triggers to your constructor / methods:
<?php
class MyEntity {
// ...
public function setField($value) {
trigger_error("This field doesn't exist anymore.", E_USER_DEPRECATED);
}
public function getField() {
trigger_error("This field doesn't exist anymore.", E_USER_DEPRECATED);
}
}
Those methods can be called through a lot of places: forms, admin bundles, twig templates and there might be some places you have missed. In PHP, it’s even possible to invoke a method dynamically from a variable value or magic methods. Having deprecation triggers will help you to detect those places and avoid fatal errors.
Working on data
Sometimes customers send you CSV files you need to upload to a table, or you need to update / remove some rows from a table, …
In that case you can just push a database migration and run it, there is no need to deploy anything.
Those kind of migrations are not tied to the application, it’s mostly daily-business or fixes for inconsistent data. As such, they should be tagged as “standalone” migrations. Your deployment script should be able to ignore them and never try to downgrade those.
More complex scenarios
In practice you will also face more complex scenarios : changing column types, moving a column to another table, …
Even for those I believe that in the vast majority of cases it’s possible to run database migrations outside deployments. You just have to think about how to avoid breaking changes. To achieve this, you’ll sometimes have to split a feature across multiple deployments.
To illustrate this with a last example, let’s say you have to move a column to a new table:
- execute a migration to add the new column
- update your code to populate the new column and the old one as well (usually it only requires to tweak an entity setter)
- deploy
- execute a migration that’ll update the new column with values from the old one
- update your code to switch all usages of old column to the new one
- deploy
- execute a migration to rename old column to column_old
Testing database migrations
Whenever it’s applicable and in order to make their execution safer, you could consider shipping a test scenario with each migration class.
As part of your Continuous Integration process, it might also be worth it to run your migration against a recent copy of production database. Live data might contain edge cases you didn’t think of during the test scenario.
Key-value storages
If you’re using key-value storages (Memcached, Redis, …) you have to be careful about key prefixes. They should either be application specific or application version specific.
Volatile data
Doctrine can cache metadata, queries and results. Those are application version specific because this data might change between two releases. To make this explicit you can do the following:
# app/config/config_prod.yml
doctrine:
orm:
metadata_cache_driver:
type: apc
namespace: "%app_version%_app_cache_orm"
result_cache_driver:
type: apc
namespace: "%app_version%_app_cache_orm"
query_cache_driver:
type: apc
namespace: "%app_version%_app_cache_orm"Here, app_version could be a parameter created during deployment and injected through an environment variable.
Unlike the typical deployment we described at the beginning of the post, where the whole cache is flushed during the downtime, here we’re keeping data from version “K” while we allow data to be saved for version “L”.
This means that during deployment the size of your cache might grow even more. You should be prepared for a memory usage multiplied by 2.
Once the deployment is finished, you’ll have to delete entries from version “K”. If your storage system doesn’t support deleting entries by prefix, it might instead be able to do some auto-cleanup of old entries once a given limit is reached.
Persistent data
While this is not specific to zero downtime deployments, some data need to persist through deployments. For those you want instead an application specific prefix.
Common use-cases are sessions or application data. If you’re using key-value storages extensively, you’ll have to go through all use cases one by one and decide of the prefix strategy accordingly.
OPcache
When it comes to symlink-based deployments, some tricks made possible by APC are not available with OPcache anymore.
Here is a post from Rasmus Lerdorf, the inventor of PHP, explaining the situation and how to proceed:
https://codeascraft.com/2013/07/01/atomic-deploys-at-etsy/
The post is mainly about Apache. If you’re using Nginx you’ll have to update the document root in the config directly, then issue a graceful reload.
EDIT: Rasmus corrected me here, for Nginx it is enough to just use $realpath_root.
@elbamarni You misread my Etsy Atomic deploys post. You definitely don't need to edit the docroot nor graceful nginx. Use $realpath_root
— Rasmus Lerdorf (@rasmus) March 10, 2016
Conclusion
Zero downtime deployments have not much to do with your deployment script, they are the natural consequence of a workflow involving continuous deployment of incremental, non-breaking changes.
Deploying without downtime actually means being able to run different versions of your application simultaneously, which might bring even more benefits. For instance, if your infrastructure is ready for horizontal scaling, you could deploy a feature to a new node and redirect a small portion of your traffic there. Then depending on visitors behavior decide whether the feature is worth it or not.
Working towards this, you’ll notice that dealing with new / legacy columns at the same time in your code is the main challenge. It’s not always easy and prone to error. As an alternative you might consider to aim for an API-centric application, which defines data structures and versioning in a more standard way.
P.S. What I’ve described here are mostly ideas, I haven’t implemented such deployments yet. If you found some inconsistencies or have experience with similar techniques, please let me know :)